
A solution for a cookieless world
With Google now matching Apple and Mozilla in their decision to pull third party cookies, the world of programmatic advertising is set for profound change. The race to find a robust contextual solution is now on. And Texture are making strong headway.

Our content-context study aimed to discover how commercial content interacts with editorial context. With fundamental changes to the two methods advertisers use to target consumers (cookies and fingerprinting), context represents a critical frontier advertisers and publishers need to better understand if they are to continue presenting digital ads effectively.
The overwhelming industry belief is
content should be matched, like-for-like
with context, to improve performance.
We conducted qualitative and quantitative research with key media players to understand industry beliefs, alongside acquiring data from a joint research project between GroupM and Newsworks; ‘Quality in Media Brand Tracking’. We then ran a series of sentiment and cognitive measures over content data and scraped contextual data.
We proved like-for-like matching has no impact on performance.

Our methodology enabled us to test whether the industry beliefs we’d received were empirically supported, as well as ascertain whether the data evinced other relationships. What we discovered were a wide range of nuanced and complex interplays which have never been seen before. For example…
Positive ads are clicked more on positive websites that make people feel in control. Less positive ads get more clicks on less positive, restrained websites that give people a low sense of control.
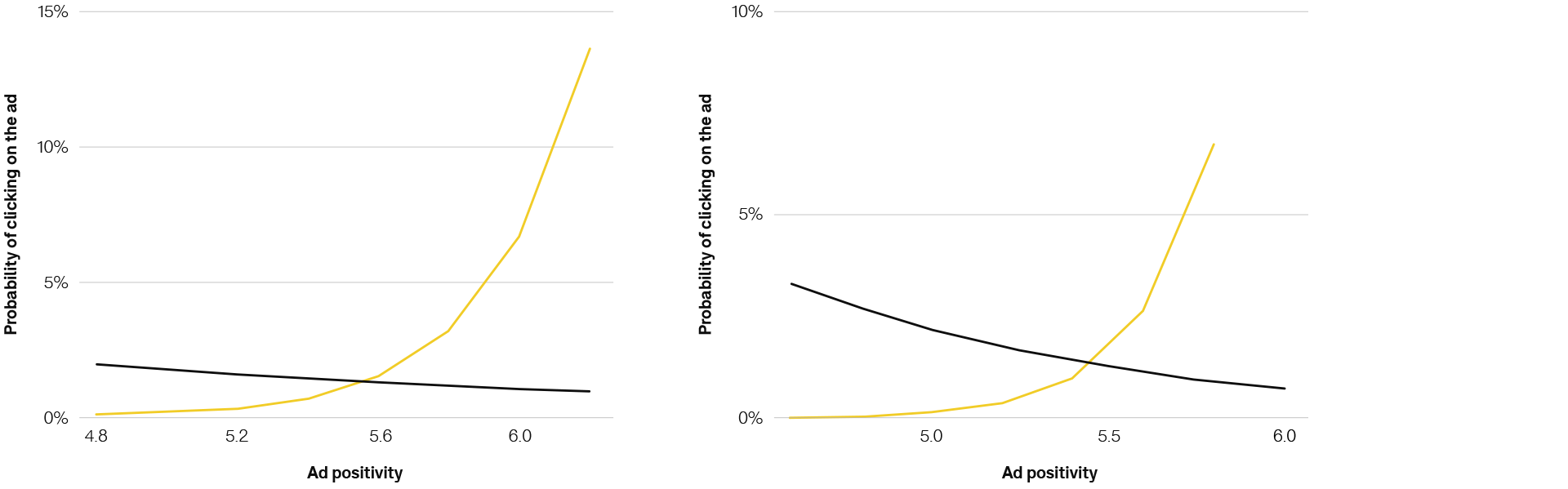
Sample findings
1. Ad positivity x website positivity
2. Ad positivity x website dominance
From the data, we discovered many significant relationships. We used these to prototype a piece of technology to demonstrate how the discoveries could be practically applied at speed and scale. We used machine learning to isolate the important predictors of recall to the unimportant ones.
We trained a regression tree on 80% of the dataset, reserving 20% to test the accuracy of its predictions.
Of all the people in the test dataset who reported remembering the ad, the model predicted 82% correctly.
This model illustrates some of the important predictors the model identified.
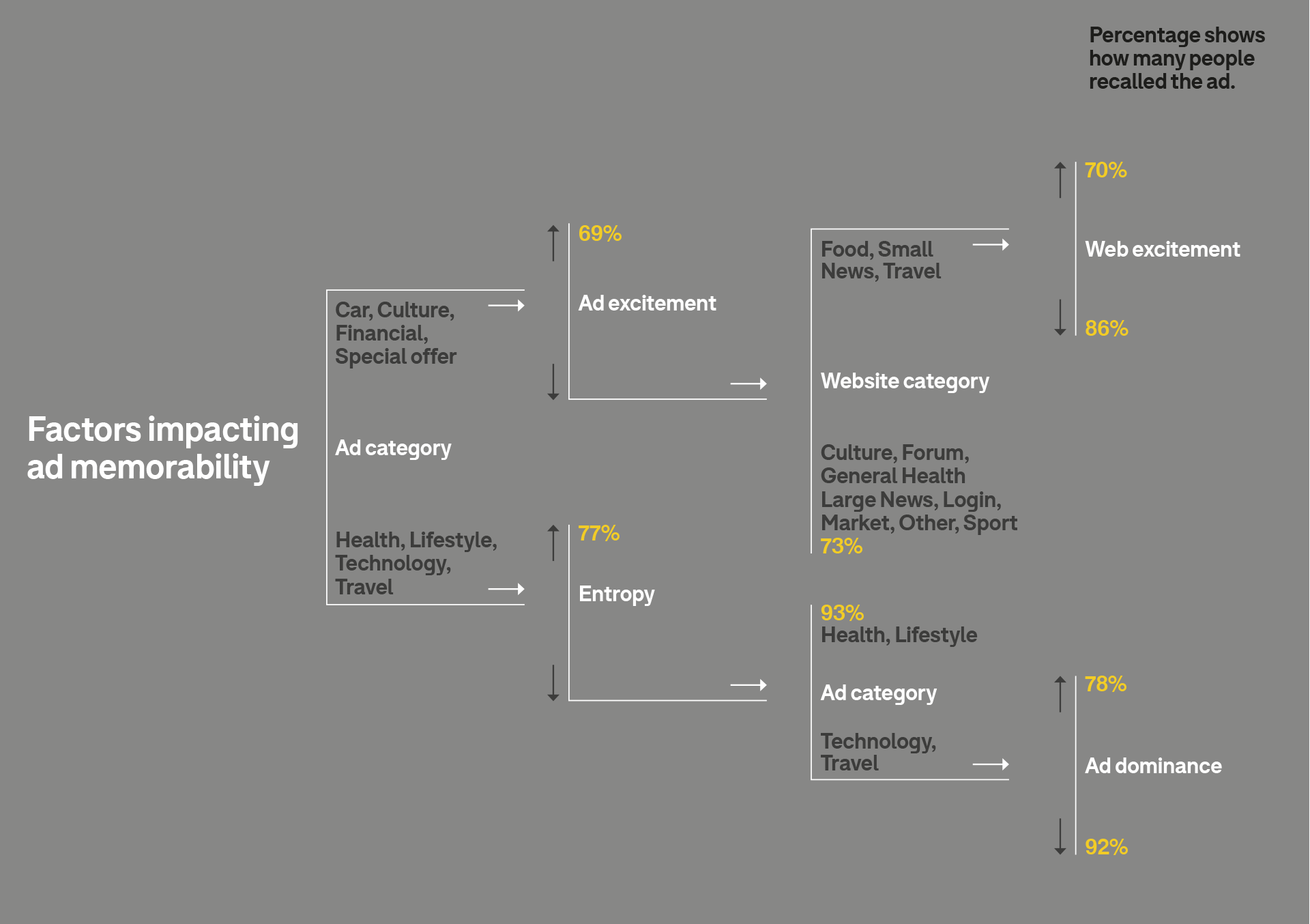
With this identified the fundamental question is whether it could be used to optimise serving? We simulated placing all the ads in the dataset in each of the potential placements. We then used our model to estimate the probability of recalling an ad. We chose the best placement for ads and then checked if the predicted recall in the optimised placements was higher than the actual recall…
Predicted optimised recall was higher than actual recall by approximately 12%. A statistically significant difference.
We are now building a similar model, trained on more data, and validated using live A/B testing. When refined this will be used to optimise live executions based on context – significantly improve performance and addressing the immediate compromise imposed by changes to current ad serving techniques.